学术成果

- 1.
Boosting Diffusion Framework for Building Vector Extraction from Remote Sensing Images
DiffVector--2025
Bingnan Yang , Mi Zhang ∗ , Yuanxin Zhao , Zhili Zhang, Xiangyun Hu, and Jianya Gong
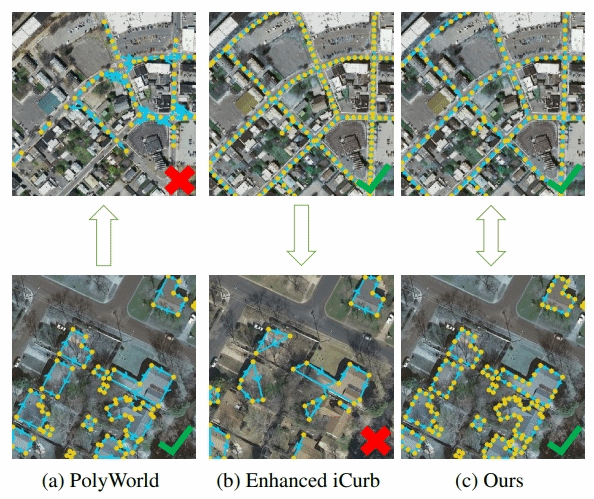
Building vector maps play an essential role in many remote sensing applications, thereby boosting the deep learning based automatic building vector extraction methods. These approaches have achieved pleasant overall accuracy, but their predict-style framework struggles with perceiving subtle details within a tiny area, such as corners and adjacent walls. In this study, we introduce a denoising diffusion framework called DiffVector to generate representations for direct building vector extraction from the remote sensing (RS) images. Firstly, we develop a hierarchical diffusion transformer (HiDiT) to conditionally generate robust representations for detecting nodes and extracting corresponding features. The conditions of HiDiT are multi-level boundary attentive maps encoded from input RS images through a topology-concentrated Swin Transformer (TC- Swin). Subsequently, an edge biased graph diffusion transformer (EGDiT) takes extracted node features as conditions to produce new visual descriptors for the adjacency matrix prediction. In EGDiT, we replace the standard self-attention operation with an edge biased attention (EBA) to inject edge information for training stabilization. Furthermore, given typical challenges of training difficulty and weak perceptive ability in convectional diffusion paradigms, we conduct an isomorphic training strategy (ITS), ensuring that the training procedures of both HiDiT and EGDiT precisely mirror the inference phase. Quantitative and qualitative experiments have evidently demonstrated that DiffVector can achieve competitive performance compared to ex- isting modern approaches, especially in metrics assessing topology quality.
- 2.
Faster Interactive Segmentation of Identical-Class Objects With One Mask in High-Resolution Remotely Sensed Imagery
IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING, VOL. 63, 2025
Zhili Zhang , Associate Member, IEEE, Jiabo Xu, Student Member, IEEE, Xiangyun Hu ,Bingnan Yang , and Mi Zhang
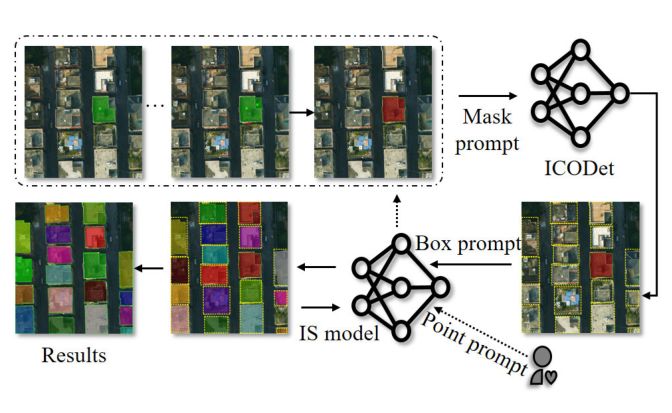
Interactive segmentation (IS) using minimal prompts like points and bounding boxes facilitates rapid image annotation, which is crucial for enhancing data-driven deep learning methods. Traditional IS methods, however, process only one target per interaction, leading to inefficiency when annotating multiple identical-class objects in remote sensing imagery (RSI). To address this issue, we present a new task—identical-class object detection (ICOD) for rapid IS in RSI. This task aims to only identify and detect all identical-class targets within an image, guided by a specific category target in the image with its mask. For this task, we propose an ICOD network (ICODet) with a two-stage object detection framework, which consists of a backbone, feature similarity analysis module (S3QFM), and an identical-class object detector. In particular, the S3QFM analyzes feature similarities from images and support objects at both feature-space and semantic levels, generating similarity maps. These maps are processed by a region proposal network (RPN) to extract target-level features, which are then refined through a simple feature comparison module and classified to precisely identify identical-class targets. To evaluate the effectiveness of this method, we construct two datasets for the ICOD task: one containing a diverse set of buildings and another containing multicategory RSI objects. Experimental results show that our method outperforms the compared methods on both datasets. This research introduces a new method for rapid IS of RSI and advances the development of fast interaction modes, offering significant practical value for data production and fundamental applications in the remote sensing community. Index Terms—Identical-class object detection (ICOD), image feature similarity analysis, interactive segmentation (IS), remote sensing images.
- 3.
agent driven topological graph extraction from remote sensing image
4–8 November 2024, Belém, Brazil
Mi Zhang , Bingnan Yang , Jianya Gong , Xiangyun Hu
Automatictopologicalgraphextractioniscriticalforintelligentremotesensingimageinterpretationandcartographicrepresentation. However, existing approaches neither adopt segmentation-based post-processing nor directly predict the graph, thereby suffering from limited scalability and poor adaptability to complex spatial structures. To address these issues, we introduce TopoSense, an innovative framework for extracting topological graphs from remote sensing images through an agent-driven approach. By employing a novel combination of reinforcement learning and neural network architectures, TopoSense autonomously navigates through pixel-level data, efficiently constructing topological representations. It not only enhances the accuracy of spatial feature detection, but also significantly reduces processing time. Experiments on the T OP - BOUNDARY and REALSCENE demonstrate its superiority in capturing intricate spatial relationships compared to traditional methods.
- 4.
Enhanced semantic-positional feature fusion network via diverse pre-trained encoders for remote sensing image water-body segmentation
Geo-spatial Information Science
Zhili Zhang, Xiangyun Hu, Bingnan Yang, Kai Deng, Mi Zhang & Dehui Zhu
In the era of increasingly advanced Earth Observation (EO) technologies, extracting pertinent information (such as water-bodies) from the Earth’s surface has become a crucial task. Deep Learning, especially via pre-trained models, currently offers a highly promising approach for the semantic segmentation of Remote Sensing Imagery (RSI). However, effectively adapting these pre-trained models to RSI tasks remains challenging. Typically, these models undergo fine-tuning for specialized tasks, involving modifications to their parameters or structure of the original architecture, which may impact their inherent generalization capabilities. Furthermore, robust pre-trained models on nature images are not specifically designed for RSI, presenting challenges in their direct application to RSI tasks. To alleviate these problems, our study introduces a light-weight Enhanced Semantic-positional Feature Fusion Network (ESFFNet), leveraging diverse pre-trained image encoders alongside extensive EO data. The proposed method begins by leveraging pre-trained encoders, specifically Vision Transformer (ViT)-based and Convolutional Neural Network (CNN)-based models, to extract deep semantic and precise positional features respectively, without additional training. Following this, we introduce the Enhanced Semantic-positional Feature Fusion Module (ESFFM). This module adeptly merges semantic features derived from the ViT-based encoder with spatial features extracted from the CNN-based encoder. Such integration is realized via multi-scale feature fusion, local and long- distance feature integration, and dense connectivity strategies, leading to a robust feature representation. Finally, the Primary Segmentation-guided Fine Extraction Module (PSFEM) further bolsters the precision of remote sensing image segmentation. Collectively, these two modules constitute our light-weight decoder, with a parameter size of less than 4 M. Our approach is evaluated on two distinct water-body datasets, indicating superiority over other leading segmentation techniques. In addition, our method also demonstrates exemplary efficacy in diverse remote sensing segmentation tasks, such as building extraction and land cover classification.

- 5.
Auniversalmodelforthematicandmulti-classvectorgraph extraction
International Journal of Applied Earth Observation and Geoinformation
Bingnan Yang , Mi Zhang , Zhili Zhang , Yuanxin Zhao , Jianya Gong
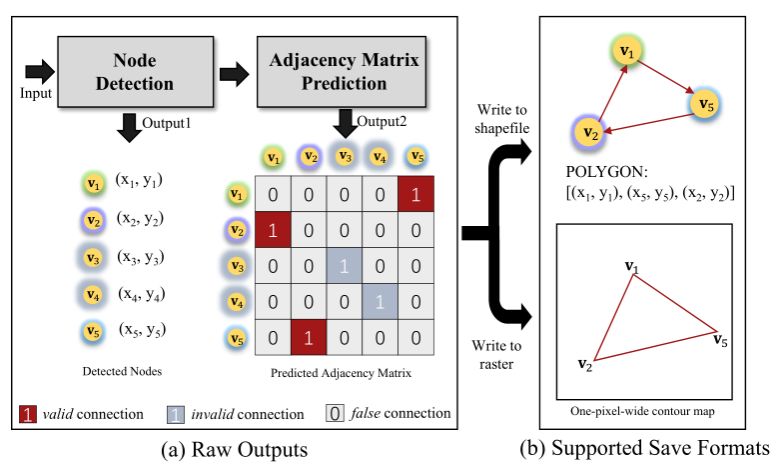
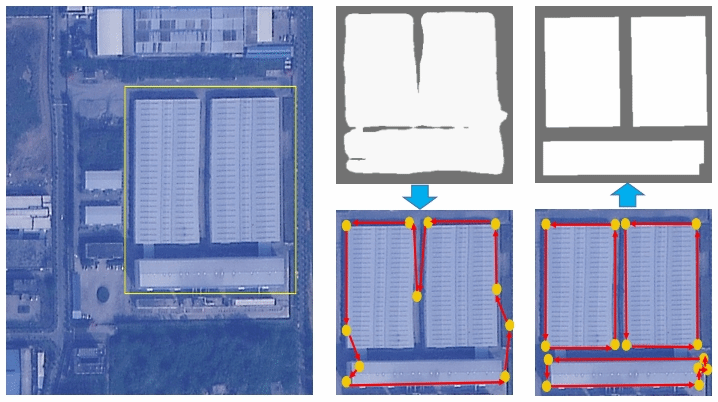
With the advancements of deep learning methodologies, there have been significant strides in automating vector extraction. However, existing methods are often tailored to specific classes and are susceptible to the category variability, especially in the case of line and polygon shape objects. In this study, we propose UniVecMapper, a universal model designed to extract directional topological graphs of targets from remote sensing images, regardless of their classes. Initially, UniVecMapper leverages a topology-concentrated node detector (TNCD) to identify nodes of targets and wraps local features. Subsequently, a directional graph (DiG) generator is employed to predict the adjacency matrix of the detected nodes. To facilitate the learning of the DiG generator, we introduce a strategy namely perturbed graph supervision (PGS), which dynamically generates adjacency matrix labels based on unordered detected nodes. Comprehensive experiments conducted on the Inria, Massachusetts, and GID datasets demonstrated UniVecMapper’s universal and competitive performance in thematic vector graph extraction. Further evaluations on the multi-class polygon-shaped dataset LandCover.ai verified that UniVecMapper achieved state-of-the-art (SOTA) performance and can easily extend to multi-class tasks.

- 6.
A Hierarchy Oriented Geo-aware Image Caption Dataset for Remote Sensing Image-Text Retrival
2403.10887v1 [cs.CV] 16 Mar 2024
Yuanxin Zhao, Mi Zhang , Member, IEEE, Bingnan Yang, Zhan Zhang, Jiaju Kang, Jianya Gong
Image-text retrieval (ITR) plays a significant role in making informed decisions for various remote sensing (RS) applications, such as urban development and disaster prevention. Nonetheless, creating ITR datasets containing vision and language modalities not only requires significant geo-spatial sampling area but also varing categories and detailed descriptions. To this end, we introduce an image caption dataset LuojiaHOG, which is geospatial-aware, label-extension-friendly and comprehensive-captioned. LuojiaHOG involves the hierarchical spatial sampling, extensible classification system to Open Geospatial Consortium (OGC) standards, and detailed caption generation. In addition, we propose a CLIP-based Image Semantic Enhancement Network (CISEN) to promote sophisticated ITR. CISEN consists of two components, namely dual-path knowledge transfer and progressive cross-modal feature fusion. The former transfers the multi-modal knowledge from the large pretrained CLIP-like model, whereas the latter leverages a visual-to-text alignment and fine-grained cross-modal feature enhancement. Comprehensive statistics on LuojiaHOG reveal the richness in sampling diversity, labels quantity and descriptions granularity. The evaluation on LuojiaHOG is conducted across various state-of-the-art ITR models, including ALBEF, ALIGN, CLIP, FILIP, Wukong, GeoRSCLIP and CISEN. We use second- and third-level labels to evaluate these vision-language models through adapter-tuning and CISEN demonstrates superior performance. For instance, it achieves the highest scores with WMAP@5 of 88.47% and 87.28% on third-level ITR tasks, respectively. In particular, CISEN exhibits an improvement of approximately 1.3% and 0.9% in terms of WMAP@5 compared to its baseline. These findings highlight CISEN advancements accurately retrieving pertinent information across image and text. LuojiaHOG and CISEN can serve as a foundational resource for future RS image-text alignment research, facilitating a wide range of vision-language applications.

- 7.
Foundation model for generalist remote sensing intelligence: Potentials and prospects — Supplementary Material
Science Bulletin. 2024 Sep 19.
Zhang M, Yang B, Hu X, Gong J#, Zhang Z.
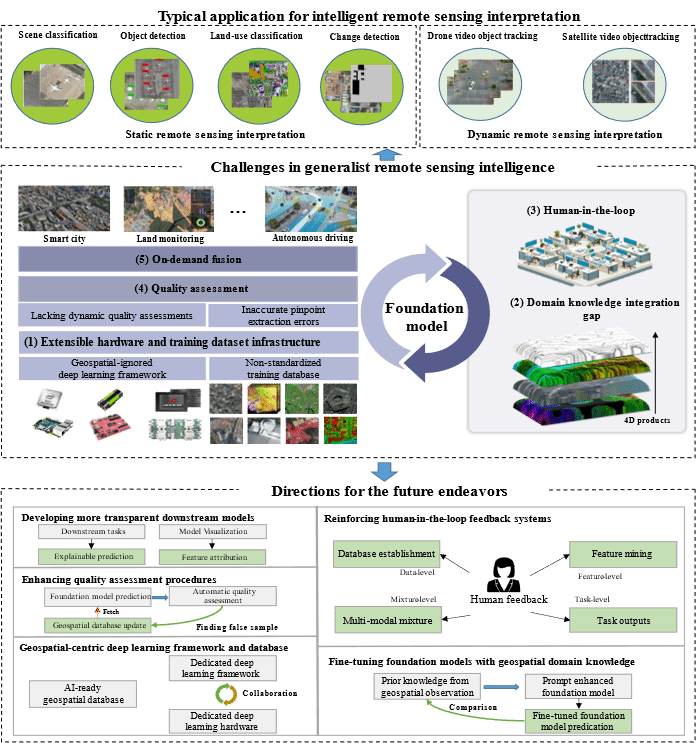
The paper systematically analyzes the progress of remote sensing big models in scene classification/retrieval, object detection, land cover classification (semantic segmentation), change detection, video tracking, and geoscience applications in the past 5 years at home and abroad. It proposes a unified computing framework for remote sensing big models, including domain specific deep learning frameworks and sample libraries, fusion and fine-tuning of multimodal geoscience domain knowledge, bidirectional human-machine feedback mechanism, quality and reliability evaluation, and transparent downstream application models. Based on this framework, the research team has developed a multimodal multi task remote sensing large model LuoJia with 2.8 billion parameters SmartSensing (Luojia The prototype system was successfully deployed at Shandong Haiyang Dongfang Aerospace Port, inspired by the project.
- 8.
Class-Agnostic Topological Directional Graph Extraction From Remote Sensing Images
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 1265-1274
Bingnan Yang, Mi Zhang, Zhan Zhang, Zhili Zhang, Xiangyun Hu
Rapid development in automatic vector extraction from remote sensing images has been witnessed in recent years. However, the vast majority of existing works concentrate on a specific target, fragile to category variety, and hardly achieve stable performance crossing different categories. In this work, we propose an innovative class-agnostic model, namely TopDiG, to directly extract topological directional graphs from remote sensing images and solve these issues. Firstly, TopDiG employs a topology-concentrated node detector (TCND) to detect nodes and obtain compact perception of topological components. Secondly, we propose a dynamic graph supervision (DGS) strategy to dynamically generate adjacency graph labels from unordered nodes. Finally, the directional graph (DiG) generator module is designed to construct topological directional graphs from predicted nodes. Experiments on the Inria, CrowdAI, GID, GF2 and Massachusetts datasets empirically demonstrate that TopDiG is class-agnostic and achieves competitive performance on all datasets.